These notes are my attempt to capture the concepts, observations and references that have helped me make sense of LLMs.
What is an LLM
A Large Language Model is a machine learning model trained to predict the next token in a sequence.
The first thing I had to unlearn: it's not a search engine. It doesn't look anything up by default. It generates responses based on patterns from training data. That distinction sounds small but it changes how you think about everything else.
Key concepts
Token
The unit everything is measured in. Roughly 3-4 characters in English text, which loosely maps to about 3/4 of a word. It varies by language and model though. Every message, every reply, every system instruction are all tokens. Most models have a hard cap on how many they can handle at once.
Parameters
The weights a model learned during training. Bigger models tend to perform better but it's not a clean relationship. Architecture, training data quality and what happened after training all matter too. Parameter count alone stopped being a reliable proxy for capability a while back.
Training vs inference
Training is the model learning from data. It happens once and is genuinely expensive. Inference is me talking to it in real time. I only ever interact during inference. The model's weights don't change mid-conversation. Whatever I tell it lives in the current context window, not in the model itself.
Knowledge cutoff
Training stopped at some date. Anything after that, the model doesn't know unless it has a search tool attached.
Hallucination
When the model generates confident-sounding but false information. It's pattern-matching without a fact-checker. More likely with obscure topics, long conversations or vague prompts. The rule I follow: verify anything that actually matters.
System prompt
Hidden instructions loaded before my first message. Sets the model's persona, rules and constraints. I never see it in most interfaces.
Temperature
Controls how predictable vs adventurous the model's word choices are.
High (0.7-1.0): varied, creative. Good for brainstorming and writing.
If AI-generated code keeps being weird, temperature is probably too high. If brainstorming outputs all sound identical, too low. Most interfaces default around 0.7. In higher-level interfaces like ChatGPT or Claude.ai, you can't set it directly so prompt phrasing does the steering instead.
Turns
A turn is one exchange: I send a message, the model replies. That's it.
The model doesn't pick up where it left off. Every turn, it re-reads the entire conversation from the beginning: the system prompt, every message I've sent, every reply it's given, any files I've attached. All of it, every single time.
There's no memory carried over between turns. No state. The conversation history only exists because it gets passed back in as part of the input. If it's not in the context window, it's gone.
This is also why the model can feel inconsistent mid-conversation. It's not drifting. It's reading more and more tokens each turn and, past a certain point, the earlier parts of the conversation start getting less attention. That re-read behavior is exactly what makes the context window worth understanding.
The context window
Everything the model can "see" at once, measured in tokens. Not memory. More like a working scratchpad. Everything the model needs to know about the current task has to fit inside it.
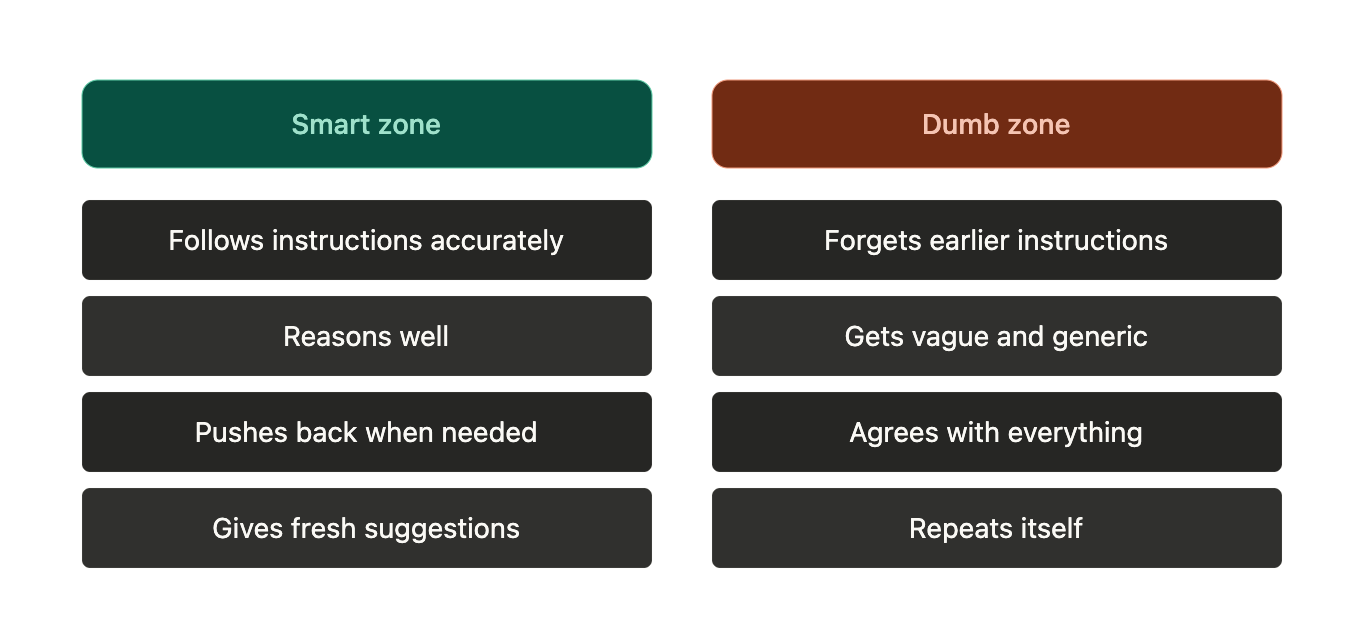
The smart zone and the dumb zone
Despite huge advertised context windows, the model doesn't process all tokens equally. This framing comes from Dex Horthy at AI Engineer World's Fair and it's the most useful mental model I've found for it.
The smart zone is the earlier portion of the context window. Full attention, good reasoning, follows instructions well.
The dumb zone kicks in as the context fills up. Tokens are still technically there, nothing gets deleted, but coherence starts degrading. The model forgets things, gets repetitive, gets vague and starts agreeing with everything.
Degradation tends to kick in well before the model hits its actual context limit. The exact threshold varies by model.
The U-curve
LLMs pay the most attention to the beginning and end of context. The middle gets ignored. So as a conversation grows, the early stuff, the instructions I set at the start, those drift into exactly the part the model stops caring about. Stanford researchers found real performance drops when relevant information sat in the middle of long contexts.
Context rot
The gradual degradation of LLM performance as context grows. Chroma ran a study across 18 frontier models and found performance decreasing with longer inputs across all tested models, not just some of them.
Warning signs:
- Repeating suggestions it already made
- "You're absolutely right" then ignores what I said
- Forgets rules or constraints from earlier
- Answers get generic and vague
What eats context fast:
- Long conversations
- Pasted files or big code blocks
- Tool integrations (can eat a significant chunk before I type anything)
- The model's own long replies, those go back in too
Context engineering
Managing what's in the context window deliberately so the model stays in the smart zone. A bit different from prompt engineering.
Prompt engineering: writing a better single prompt.
Context engineering: designing what information reaches the model at all, instructions, retrieved documents, tool outputs, conversation history.
What I do in practice to stay in the smart zone:
- Keep prompts specific. (Vague in, vague out!)
- Start fresh often. New topic means new conversation.
- Front-load the important stuff. Given the U-curve, critical instructions buried mid-conversation get less attention.
- When context gets full, prefer a manual handoff over letting the model auto-summarize. A model that's already degraded writing its own summary is not ideal. I use Matt Pocock's /handoff skill for this.
- Don't trust large context windows blindly. 1M tokens doesn't mean 1M tokens of reliable reasoning.
- Verify anything that matters. Hallucination is real.
A degraded model writing its own summary is not a reliable summary!
What I'm still figuring out
RAG (Retrieval-Augmented Generation)
Instead of stuffing everything into the context window, the system retrieves only the relevant pieces when needed, pulling from a database, a document store or a knowledge base. The model never sees the full corpus, just what's relevant to the current query.
Embeddings
Numerical representations of text that capture meaning. Similar ideas end up close together in vector space, which makes semantic search possible.
Embeddings are the foundation of RAG, vector databases and many AI memory systems.
Training
I understand the basic idea: expose the model to enormous amounts of text and for each token it predicts, adjust the weights slightly based on whether it was right. Repeat billions of times. But I don't have a clear picture of what that actually looks like at scale yet.